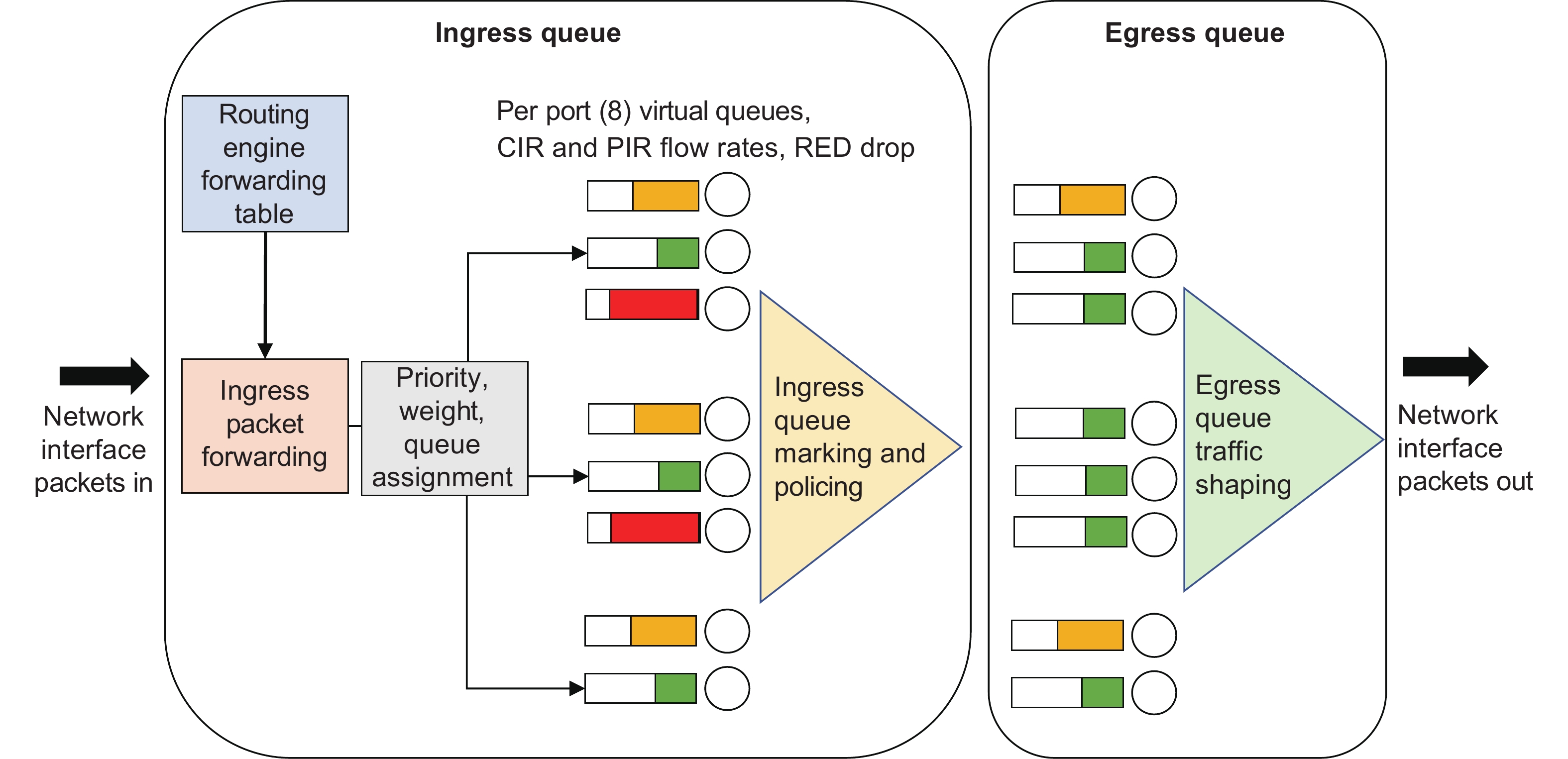
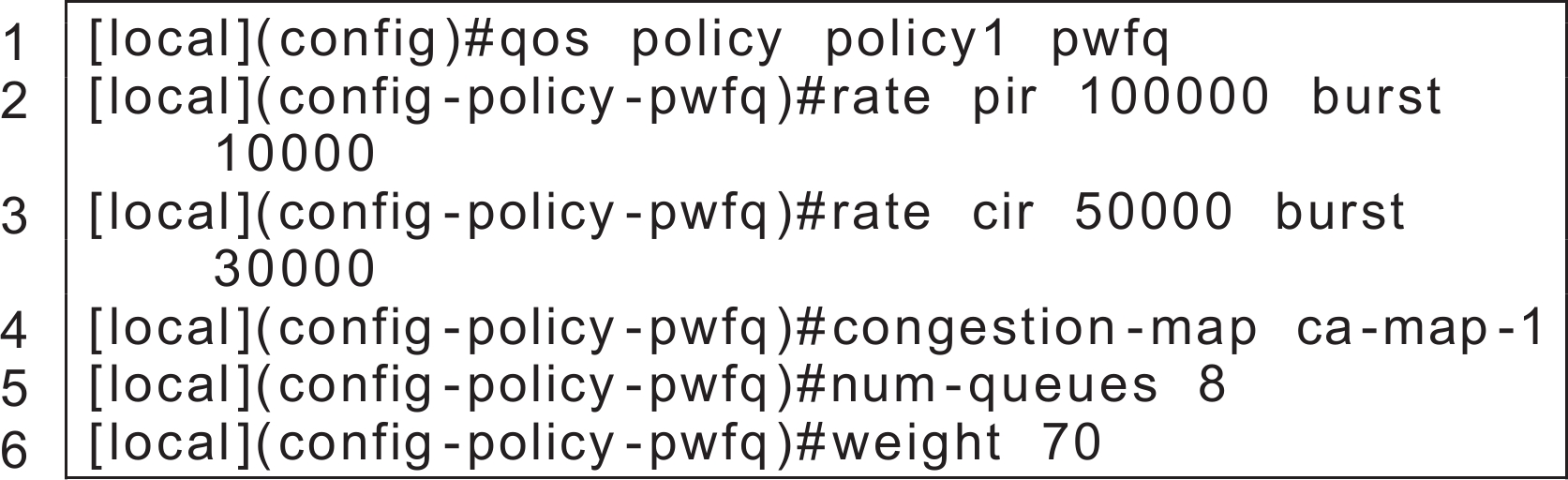
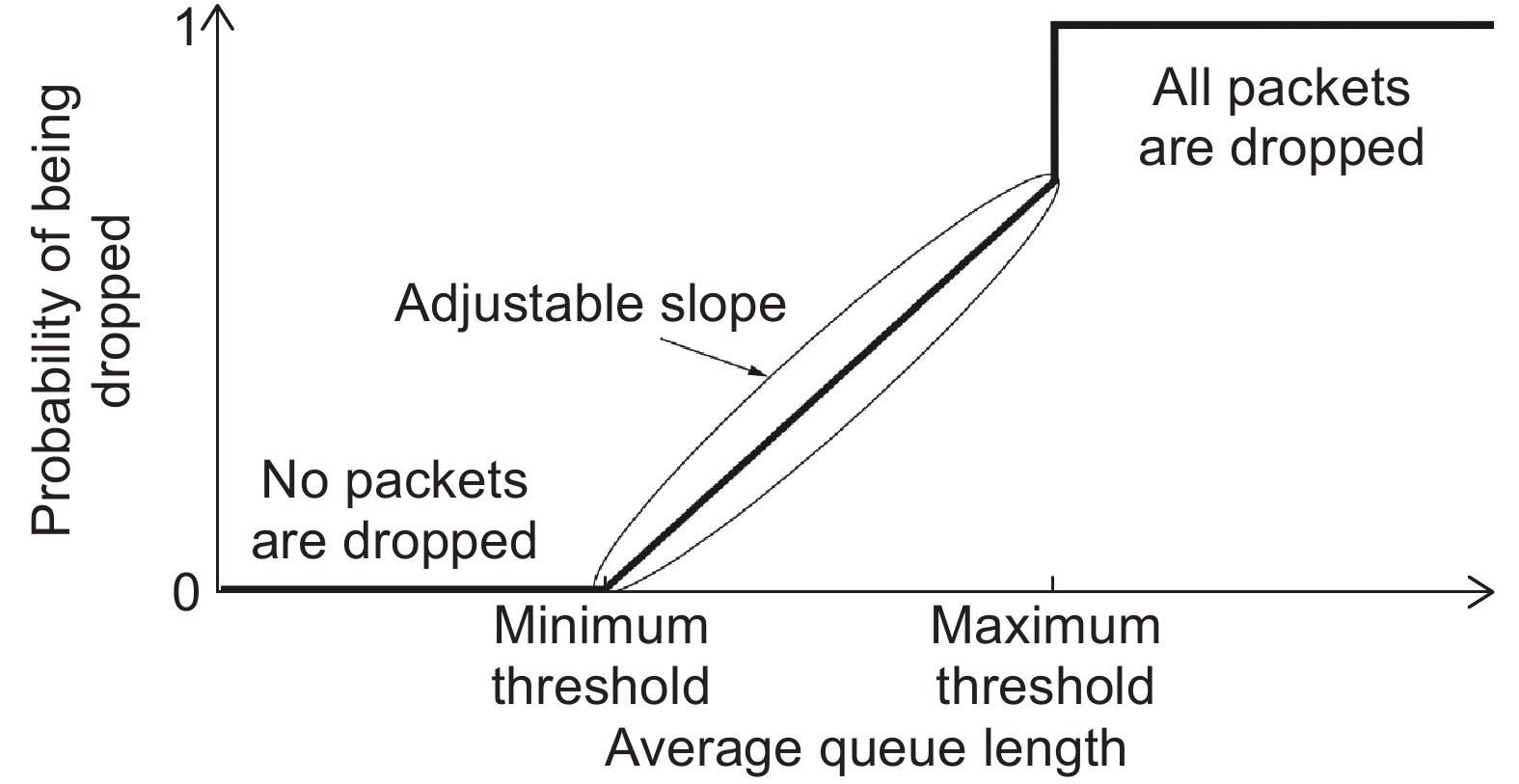
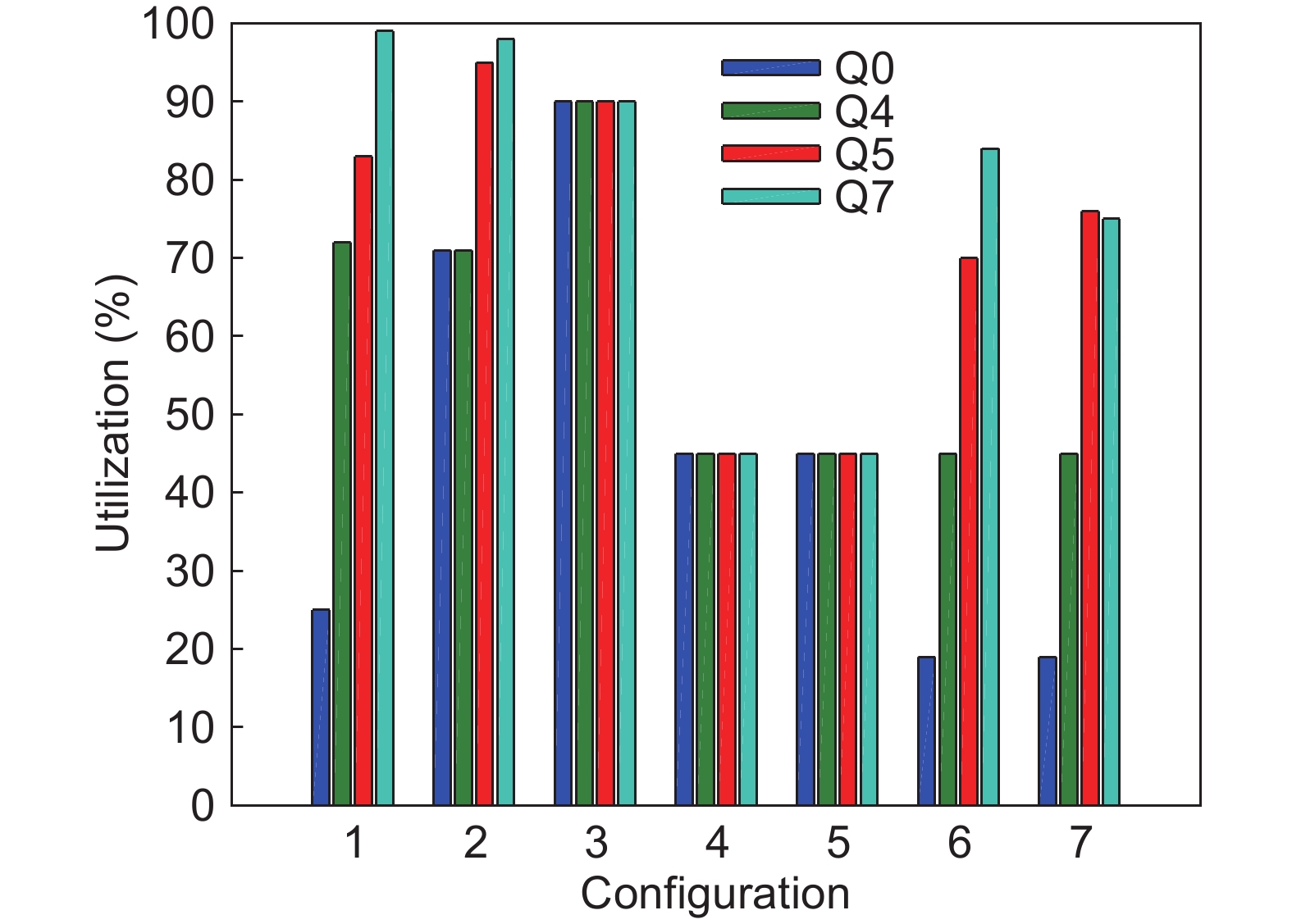
|
|
|
|
Received: 25 August 2021
Online: 07 December 2021
|
|
|
| 1 |
ETSI, System architecture for the 5G system, 3GPP TS 23.501, version 15.3. 0, 2018.
|
| 2 |
X. Foukas, G. Patounas, A. Elmokashfi, and M. K. Marina Network slicing in 5G: Survey and challenges[J]. IEEE Commun. Mag., 2017, 55 (5): 94- 100
doi: 10.1109/MCOM.2017.1600951
|
| 3 |
Ericsson AB, Router 6675, Technical specifications, 2019.
|
| 4 |
D. R. Hanks Jr. and H. Reynolds, Juniper MX Series. Sebastopol, CA, USA: O’Reilly Media, 2012.
|
| 5 |
D. Kreutz, F. M. V. Ramos, P. E. Veríssimo, C. E. Rothenberg, S. Azodolmolky, and S. Uhlig Software-defined networking: A comprehensive survey[J]. Proc. IEEE, 2015, 103 (1): 14- 76
doi: 10.1109/JPROC.2014.2371999
|
| 6 |
Cisco Systems, Quality of Service (QoS) configuration guide, Cisco IOS, 2018.
|
| 7 |
R. S. Sutton and A. G. Barto, Reinforcement Learning - An Introduction. 2nd ed. Cambridge, MA, USA: MIT Press, 2018.
|
| 8 |
L. P. Kaelbling, M. L. Littman, and A. R. Cassandra Planning and acting in partially observable stochastic domains[J]. Artif. Intell., 1998, 101 (1&2): 99- 134
doi: 10.1016/S0004-3702(98)00023-X
|
| 9 |
Cisco Systems, QoS: Color-aware policer, Cisco IOS documentation, 2005.
|
| 10 |
C. Semeria, Supporting differentiated service classes: Queue scheduling disciplines, Juniper Networks Whitepaper, 2001.
|
| 11 |
H. Zhang Service disciplines for guaranteed performance service in packet-switching networks[J]. Proc. IEEE, 1995, 83 (10): 1374- 1396
doi: 10.1109/5.469298
|
| 12 |
Cisco Systems, DiffServ – the scalable end-to-end QoS model, WhitePaper, 2005.
|
| 13 |
T. X. Brown, Switch packet arbitration via queue-learning, in Proc. 14th Int. Conf. Neural Information Processing Systems: Natural and Synthetic, Vancouver, Canada, 2001, pp. 1337–1344.
|
| 14 |
J. A. Boyan and M. L. Littman, Packet routing in dynamically changing networks: A reinforcement learning approach, in Proc. 6th Int. Conf. Neural Information Processing Systems, Denver, CO, USA, 1993, pp. 671–678.
|
| 15 |
Z. Mammeri Reinforcement learning based routing in networks: Review and classification of approaches[J]. IEEE Access, 2019, 7: 55916- 55950
doi: 10.1109/ACCESS.2019.2913776
|
| 16 |
A. Mestres, A. Rodriguez-Natal, J. Carner, P. Barlet-Ros, E. Alarcón, M. Solé, V. Muntés-Mulero, D. Meyer, S. Barkai, M. J. Hibbett, et al. Knowledge-defined networking[J]. SIGCOMM Comput. Commun. Rev., 2017, 47 (3): 2- 10
doi: 10.1145/3138808.3138810
|
| 17 |
T. C. K. Hui and C. K. Tham Adaptive provisioning of differentiated services networks based on reinforcement learning[J]. IEEE Trans. Syst. Man Cybern. C (Appl. Rev.), 2003, 33 (4): 492- 501
doi: 10.1109/TSMCC.2003.818472
|
| 18 |
J. Rao, X. P. Bu, C. Z. Xu, L. Y. Wang, and G. Yin, VCONF: A reinforcement learning approach to virtual machines auto-configuration, in Proc. 6th Int. Conf. Autonomic Computing, Barcelona, Spain, 2009, pp. 137–146.
|
| 19 |
A. da Silva Veith, F. R. de Souza, M. D. de Assun??o, L. Lefèvre, and J. C. S. dos Anjos, Multi-objective reinforcement learning for reconfiguring data stream analytics on edge computing, in Proc. 48th Int. Conf. Parallel Processing, Kyoto, Japan, 2019, p.106.
|
| 20 |
A. Bar-Hillel, A. Di-Nur, L. Ein-Dor, R. Gilad-Bachrach, and Y. Ittach, Workstation capacity tuning using reinforcement learning, in Proc. ACM/IEEE Conf. Supercomputing, Reno, NV, USA, 2007, p. 32.
|
| 21 |
C. H. Yu, J. L. Lan, Z. H. Guo, and Y. X. Hu DROM: Optimizing the routing in software-defined networks with deep reinforcement learning[J]. IEEE Access, 2018, 6: 64533- 64539
doi: 10.1109/ACCESS.2018.2877686
|
| 22 |
T. A. Q. Pham, Y. Hadjadj-Aoul, and A. Outtagarts, Deep reinforcement learning based QoS-aware routing in knowledge-defined networking, in Proc. 14th EAI Int. Conf. Heterogeneous Networking for Quality, Reliability, Security and Robustness, Ho Chi Minh City, Vietnam, 2019, pp. 14–26.
|
| 23 |
X. Y. You, X. J. Li, Y. D. Xu, H. Feng, and J. Zhao, Toward packet routing with fully-distributed multi-agent deep reinforcement learning, in Proc. of 2019 Int. Symp. Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOPT), Avignon, France, 2019, doi: 10.23919/WiOPT47501.2019.9144110.
|
| 24 |
X. Mai, Q. Z. Fu, and Y. Chen, Packet routing with graph attention multi-agent reinforcement learning, arXiv preprint arXiv: 2107.13181, 2021.
|
| 25 |
R. Bhattacharyya, A. Bura, D. Rengarajan, M. Rumuly, S. Shakkottai, D. Kalathil, R. K. P. Mok, and A. Dhamdhere, QFlow: A reinforcement learning approach to high QoE video streaming over wireless networks, in Proc. 20th ACM Int. Symp. Mobile Ad Hoc Networking and Computing, Catania, Italy, 2019, pp. 251–260.
|
| 26 |
J. Prados-Garzon, T. Taleb, and M. Bagaa, LEARNET: Reinforcement learning based flow scheduling for asynchronous deterministic networks, in Proc. of 2020 IEEE Int. Conf. Communications, Dublin, Ireland, 2020, doi: 10.1109/ICC40277.2020.9149092.
|
| 27 |
P. Pinyoanuntapong, M. Lee, and P. Wang, Distributed multi-hop traffic engineering via stochastic policy gradient reinforcement learning, in Proc. of 2019 IEEE Global Communications Conf. (GLOBECOM), Waikoloa, HI, USA, https://webpages.uncc.edu/pwang13/pub/routing.pdf, 2019.
|
| 28 |
J. Chavula, M. Densmore, and H. Suleman, Using SDN and reinforcement learning for traffic engineering in UbuntuNet Alliance, in Proc. of 2016 Int. Conf. Advances in Computing and Communication Engineering (ICACCE), Durban, South Africa, 2016, pp. 349–355.
|
| 29 |
K. F. Xiao, S. W. Mao, and J. K. Tugnait TCP-Drinc: Smart congestion control based on deep reinforcement learning[J]. IEEE Access, 2019, 7: 11892- 11904
doi: 10.1109/ACCESS.2019.2892046
|
| 30 |
B. Liu, Q. M. Xie, and E. Modiano, Reinforcement learning for optimal control of Queueing systems, in Proc. of the 57th Annu. Allerton Conf. Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2019, pp. 663–670.
|
| 31 |
J. G. Dai and M. Gluzman, Queueing network controls via deep reinforcement learning, arXiv preprint arXiv: 2008.01644, 2021.
|
| 32 |
M. Raeis, A. Tizghadam, and A. Leon-Garcia Queue-learning: A reinforcement learning approach for providing quality of service[J]. Proc. AAAI Conf. Artif. Intell., 2021, 35 (1): 461- 468
|
| 33 |
A. Kattepur, S. David, and S. Mohalik, Automated configuration of router port queues via model-based reinforcement learning, in Proc. of 2021 IEEE Int. Conf. Communications Workshops, Montreal, Canada, 2021, pp. 1–6.
|
| 34 |
S. Floyd and V. Jacobson Random early detection gateways for congestion avoidance[J]. IEEE/ACM Trans. Netw., 1993, 1 (4): 397- 413
doi: 10.1109/90.251892
|
| 35 |
M. Bertoli, G. Casale, and G. Serazzi JMT: Performance engineering tools for system modeling[J]. ACM SIGMETRICS Perform. Eval. Rev., 2009, 36 (4): 10- 15
doi: 10.1145/1530873.1530877
|
| 36 |
H. Kurniawati, D. Hsu, and W. S. Lee, SARSOP: Efficient point-based POMDP planning by approximating optimally reachable belief spaces, in Proc. Robotics: Science and Systems IV, Zurich, Switzerland, doi: 10.15607/RSS.2008.IV.0092008.
|
| 37 |
E. D. Lazowska, J. Zahorjan, G. S. Graham, and K. C. Sevcik, Quantitative System Performance, Computer System Analysis Using Queueing Network Models. Upper Saddle River, NJ, USA: Prentice-Hall, 1984.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|